Polyglot (b01lers CTF 2026) - writeup
ENI participated in b01lers CTF 2026 as part of the team Infobahn. The CTF format was a hybrid of two styles: Jeopardy and King of the Hill (KotH). KotH is a competition format where participants compete to achieve the highest score on a given challenge.
I spent most of my time on the KotH challenge called "Polyglot". The objective was to create a polyglot script that ran in as many specified programming languages as possible. The team that supported the most languages would win, with the shortest code serving as a tiebreaker. All submissions were required to read three numbers from standard input and calculate a ** b % m.
There were 19 languages available: bash, c, elixir, fish, golfscript, haskell, j, julia, lua, perl, scheme, rust, typescript, whitespace, erlang, java, odin, python, and zig.
By the end of the competition, we managed to create a polyglot supporting 14 out of 19 languages. This was the highest count among all participants, and our code was even shorter than those of the 2nd and 3rd place teams, which each supported 13 languages.
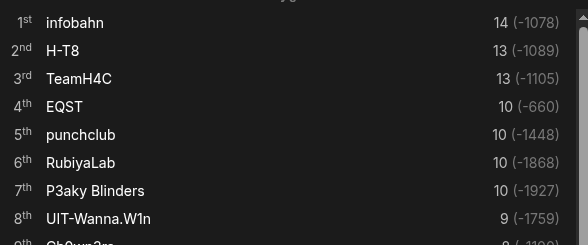
I want to explain how this was possible and walk through our process step by step.
Disclaimers
- I didn't find all of the payloads myself; most were discovered by my teammates or LLMs. However, I eventually came to understand how they worked in order to integrate them with other languages or shorten the overall code. Therefore, the solve process described here isn't exactly how things unfolded, but I believe it accurately represents the ideal approach to these kinds of problems.
- The actual solve process was much messier, involving many approaches that either failed or were eventually discarded. I will only explain what remained in the final payload.
Perl + TypeScript
Let's start with something simple: Perl and TypeScript.
1//1;use bigint;print+(<>+0)**<>%<>;__END__
var [a,b,c]=(await Bun.stdin.text()).split`\n`.map(BigInt);console.log(a**b%c+``)/*
*/
- In TypeScript,
//marks the start of a single-line comment. In Perl, it is a logical OR operator. Consequently, everything after//on the first line is ignored by TypeScript but remains valid for Perl. - When Perl encounters
__END__, it ignores everything that follows.
+ Julia
1//1#=
;1//1;use bigint;print+(<>+0)**<>%<>;__END__
var [a,b,c]=(await Bun.stdin.text()).split`\n`.map(BigInt);console.log(a**b%c+``)/*
=#
print(powermod(parse.(Int,eachline())...))
#=
*///=#
- In Julia,
//is the rational division operator. Similar to Perl, this allows the line to remain syntactically valid. - For Perl,
#=is simply the start of a single-line comment (#) followed by an=, which is ignored. Conversely, Julia treats#=as the start of a multiline comment that ends with=#.
+ Scheme
#!/usr/bin/perl
1//1#=
;1//1;use bigint;print+(<>+0)**<>%<>;__END__
var [a,b,c]=(await Bun.stdin.text()).split`\n`.map(BigInt);console.log(a**b%c+``)/*
=#
print(powermod(parse.(Int,eachline())...))
#=!#
(write(modulo(expt(read)(read))(read)))
#!
*///=##!#
- We added a shebang to the first line. Most programming languages simply ignore this line.
- In Julia, it is treated as a standard comment.
- In TypeScript, it is treated as a comment only if it appears on the first line.
- Perl checks if the shebang includes the word
perl. The other parts is ignored.
- In Scheme,
#!is treated differently depending on the runtime.Guile, which was used in this challenge, treats this as the start of a multiline comment that ends with!#.
+ Fish
#!/usr/bin/perl ;n{|!u?:-1}${%&:&*@:}O<}1&
1//1#=
;1//1;use bigint;print+(<>+0)**<>%<>;__END__
var [a,b,c]=(await Bun.stdin.text()).split`\n`.map(BigInt);console.log(a**b%c+``)/*
=#
print(powermod(parse.(Int,eachline())...))
#=!#
(write(modulo(expt(read)(read))(read)))
#!
*///=##!#
- Fish does not recognize the shebang, so the first line is treated as part of the program.
- Unlike most programming languages that parse code from left to right and top to bottom, Fish uses instructions to change the direction of the program counter.
- The program starts at the top left, moving to the right.
#is an instruction that reflects the direction, causing it to move left. - The program wraps around in a "Pac-Man" style and ignores all whitespace. Thus, the next instruction encountered is
&, and continues to the left. - I am not entirely sure how the other parts work, but my teammate Shiro managed to create such a compact payload for this complex esoteric language.
+ Bash
#!/usr/bin/perl ;n{|!u?:-1}${%&:&*@:}O<}1&
1//1#=<<Q
;1//1;use bigint;print+(<>+0)**<>%<>;__END__
var [a,b,c]=(await Bun.stdin.text()).split`\n`.map(BigInt);console.log(a**b%c+``)/*
=#
print(powermod(parse.(Int,eachline())...))
#=!#
(write(modulo(expt(read)(read))(read)))
#!
Q
read a;read b;read m;for((r=1;b--;)){((r=r*a%m))};echo $r;exit
*///=##!#
- Bash usually handles
#as the start of a one-line comment. Hence, the shebang is treated as a comment. - However,
#must be followed by a space-like character if it is in the middle of the line. Otherwise, it is treated as part of a token. Here,1//1#=is treated as a single token, and bash tries to execute it as a command. <<Qis the start of a heredoc, which ends at a line that exactly matchesQ.1//1#=is obviously an invalid command. However, bash doesn't stop even if it encounters an invalid command.- After it executes the
exitcommand, the process halts and ignores everything that follows.
+ Golfscript
#!/usr/bin/perl ;n{|!u?:-1}${%&:&*@:}O<}1&
1//1#=<<Q
;1//1;use bigint;print+(<>+0)**<>%<>;__END__
var [a,b,c]=(await Bun.stdin.text()).split`\n`.map(BigInt);console.log(a**b%c+``)/*
=#
print(powermod(parse.(Int,eachline())...))
#=!#
(write(modulo(expt(read)(read))(read)))
#!
Q
read a;read b;read m;for((r=1;b--;)){((r=r*a%m))};echo $r;exit
"#{a,b,m=Stack[0].to_s.split.map(&:to_i);p a**b%m;exit}"
*///=##!#
- Golfscript has an interesting feature where if you write
"#{<ruby code>}", the Ruby code will run and the result is treated as a string in Golfscript. - The important thing is that this happens in the tokenizer, not at runtime. Hence, if the Ruby code runs
exit, the program ends before Golfscript even starts. - Therefore, anything outside
"#{...;exit}"will be ignored.
+ Elixir
#!/usr/bin/perl ;n{|!u?:-1}${%&:&*@:}O<}1&
1<2||~r//r#=<<Q
;1||~r//r;~S|1;use bigint;print+(<>+0)**<>%<>;__END__|;'
var [a,b,c]=(await Bun.stdin.text()).split`\n`.map(BigInt);console.log(a**b%c+``)/*
=#
print(powermod(parse.(Int,eachline())...))
#=!#
(write(modulo(expt(read)(read))(read)))
#|
Q
read a;read b;read m;for((r=1;b--;)){((r=r*a%m))};echo $r;exit
'
{_,[a,b,m]}=:io.fread([],'~d~d~d');IO.puts(rem(a**b,m));~S|
"#{a,b,m=Stack[0].to_s.split.map(&:to_i);p a**b%m;exit}"
*///=##a|#
- In Elixir,
//is a range step operator, which must be used like1..9//2. This kind of syntax is invalid for some languages, so we need to find a different way. - Instead, we used the fact that
~r//is treated as an empty regex. - For most languages,
~r//ris valid syntax, but will raise an error becauseris undefined. To tackle this, we prepended it with1<2||so that expressions after||will not be evaluated due to short-circuiting. - For the third row, we prepended it with
1||for the same reason. This will work for most languages because1is treated as truthy. The exception is Julia, which requires the value to be a boolean, but Julia already treats the third line as a comment. - Elixir supports multiline strings with
'...'. We used this to negate most of the current code.- However, we cannot negate the Golfscript code in the same way, because anything between
'...'is also treated as a string for Golfscript too. We need the whole"#{...}"to be treated as a string, so it must exist outside'...'. To tackle this we used another way to express multi-line strings:~S|...|. This is called a sigil. - In the same way, we used it to negate the Perl code. For Perl,
~Sis the same as~"S", and will flip the bits of its binary representation. - We changed the second multi-line comment for Scheme from
#!...!#to#|...|#in order to share the character|and save some bytes.
- However, we cannot negate the Golfscript code in the same way, because anything between
+ Rust
#![doc="perl ;n{|!u?:-1}${%&:&*@:}O<}1&
1<2||~r//r#=<<Q
;1||~r//r;~S|1;use bigint;print+(<>+0)**<>%<>;__END__|;'
var [a,b,c]=(await Bun.stdin.text()).split`\n`.map(BigInt);console.log(a**b%c+``)/*
=#
print(powermod(parse.(Int,eachline())...))
#=!#
(write(modulo(expt(read)(read))(read)))
#|
"]
fn main(){let s=std::io::read_to_string(std::io::stdin()).unwrap();let mut i=s.lines();let[a,b,m]=[0;3].map(|_|i.next().unwrap().parse().unwrap());print!("{}",(0..b).fold(1,|r,_|r*a%m))}/*
Q
read a;read b;read m;for((r=1;b--;)){((r=r*a%m))};echo $r;exit
'
{_,[a,b,m]}=:io.fread([],'~d~d~d');IO.puts(rem(a**b,m));~S|
"#{a,b,m=Stack[0].to_s.split.map(&:to_i);p a**b%m;exit}"
*///=##a|#
- Rust doesn't support a shebang. Instead, we can use
#![...], which will be treated as an inner attribute. - Rust also supports multi-line strings using
"...", so we can negate most of the code using#![doc="..."].
+ J
#![doc=r#"perl ;n{|!u?:-1}${%&:&*@:}O<}1&
1<2||~r//r#=0!:0'echo{:d|^/x:2{.d=.".;._2[1!:1]3'<<Q
;1||~r//r;~S|1;use bigint;print+(<>+0)**<>%<>;__END__|;'
var [a,b,c]=(await Bun.stdin.text()).split`\n`.map(BigInt);console.log(a**b%c+``)/*
=#
print(powermod(parse.(Int,eachline())...))
#=!#
(write(modulo(expt(read)(read))(read)))
#|
"#]
fn main(){let s=std::io::read_to_string(std::io::stdin()).unwrap();let mut i=s.lines();let[a,b,m]=[0;3].map(|_|i.next().unwrap().parse().unwrap());print!("{}",(0..b).fold(1,|r,_|r*a%m))}/*
Q
read a;read b;read m;for((r=1;b--;)){((r=r*a%m))};echo $r;exit
'
{_,[a,b,m]}=:io.fread([],'~d~d~d');IO.puts(rem(a**b,m));~S|
"#{a,b,m=Stack[0].to_s.split.map(&:to_i);p a**b%m;exit}"
*///=##a|#
- J also supports the shebang, so the first line will be ignored.
- J evaluates from right to left. I'm not fully sure what
<<does, but it seems it is valid. 0!:0'echo{:d|^/x:2{.d=.".;._2[1!:1]3'is the actual J code.0!:0evaluates the string between the following'...'.- Everything else is almost entirely invalid for J, and it will raise an error. However, for some reason, J always returns 0 as a return code. The error will be output to stderr, so it doesn't affect the runner, which only checks stdout.
- The
"characters inside the J code would interfere with the Rust string, but we can bypass this by using an alternative way to express strings in Rust:r#"..."#.
+ C
#![doc=r#"perl ;n{|!u?:-1}${%&:&*@:}O<}1&/\
1<2||~r//r#=0!:0'echo{:d|^/x:2{.d=.".;._2[1!:1]3'<<Q\\
;1||~r//r;~S|1;use bigint;print+(<>+0)**<>%<>;__END__|;'\
var [a,b,c]=(await Bun.stdin.text()).split`\n`.map(BigInt);console.log(a**b%c+``)/*
main(r,a,b,m){for(scanf("%d%d%d",&a,&b,&m);b--;)r=r*a%m;printf("%d",r);}/*
=#
print(powermod(parse.(Int,eachline())...))
#=!#
(write(modulo(expt(read)(read))(read)))
#|
"#]
fn main(){let s=std::io::read_to_string(std::io::stdin()).unwrap();let mut i=s.lines();let[a,b,m]=[0;3].map(|_|i.next().unwrap().parse().unwrap());print!("{}",(0..b).fold(1,|r,_|r*a%m))}/*
Q\
read a;read b;read m;for((r=1;b--;)){((r=r*a%m))};echo $r;exit
'
{_,[a,b,m]}=:io.fread([],'~d~d~d');IO.puts(rem(a**b,m));~S|
"#{a,b,m=Stack[0].to_s.split.map(&:to_i);'/\\';p a**b%m;exit}"*///=##a|#
- Most C compilers like GCC or Clang do not support shebangs. However, the compiler used here is TCC, which does. Here, the first line that starts with
#!is treated as a comment. - C has a feature where if a line containing a single-line comment ends with
\, it negates the line-break and treats the next line as a comment as well. This enables us to have the 2nd to 4th lines treated as comments. - This breaks Fish because
\mirrors the direction upwards, moving the next instruction to the last line. We added some code to the last line so that it goes back to the first line.
+ Lua
#![doc=r#"perl ;n{|!u?:-1}${%&:&*@:}O<}1&/\
q=[[] ]<[[1] ]||~r//r#=#0!:0'echo{:d|^/x:2{.d=.".;._2[1!:1]3'<<Q\\
;1||~r//r;~S|1;use bigint;print+(<>+0)**<>%<>;__END__|;'\
var[q,b,c]=(await Bun.stdin.text()).split`\n`.map(BigInt);console.log(q**b%c+``)/*
main(r,a,b,m){for(scanf("%d%d%d",&a,&b,&m);b--;)r=r*a%m;printf("%d",r);}/*
=#
print(powermod(parse.(Int,eachline())...))
#=!#
(write(modulo(expt(read)(read))(read)))
#|
"#]
fn main(){let s=std::io::read_to_string(std::io::stdin()).unwrap();let mut i=s.lines();let[a,b,m]=[0;3].map(|_|i.next().unwrap().parse().unwrap());print!("{}",(0..b).fold(1,|r,_|r*a%m))}/*
Q\
read a;read b;read m;for((r=1;b--;)){((r=r*a%m))};echo $r;exit
]]a,b,m=io.read("n","n","n");r=1;for _=1,b do r=r*a%m end;print(r)--[[
'
{_,[a,b,m]}=:io.fread([],'~d~d~d');IO.puts(rem(a**b,m));~S|
"#{a,b,m=Stack[0].to_s.split.map(&:to_i);'/\\';p a**b%m;exit}"*///=##a|#;]]
- Lua also supports shebangs, so the first line is ignored.
- Lua treats
[[...]]as a multi-line string. This is convenient because most languages treat[[] ]as a list containing an empty list, while Lua treats the following code as a string. - However, Lua doesn't support writing an expression on its own; it must be a statement. For example,
[[...]]is invalid, butx=[[...]]is valid.- This is a problem for Perl because all variables in Perl must start with a sigil, such as
$,@, or%. This would not be valid for many languages, including Lua. - However, there is an exception: you can write
q=...=to express a string in Perl. - In TypeScript, you cannot use a variable without declaring it. However, TypeScript also supports hoisting, where you can declare a variable after it is used.
- This is a problem for Perl because all variables in Perl must start with a sigil, such as
+ Haskell
#![doc=r#"perl ;n{|!u?:-1}${%&:&*@:}O<}1&/\
q=[[] ]<[[1] ]||~r//r#=#1{-0!:0'echo{:d|^/x:2{.d=.".;._2[1!:1]3'<<Q\\
;1||~r//r;~S|1;use bigint;print+(<>+0)**<>%<>;__END__|;'\
var[q,b,c]=(await Bun.stdin.text()).split`\n`.map(BigInt);console.log(q**b%c+``)/*
main(r,a,b,m){for(scanf("%d%d%d",&a,&b,&m);b--;)r=r*a%m;printf("%d",r);}/*
=#
print(powermod(parse.(Int,eachline())...))
#=!#
(write(modulo(expt(read)(read))(read)))
#|
"#]
fn main(){let s=std::io::read_to_string(std::io::stdin()).unwrap();let mut i=s.lines();let[a,b,m]=[0;3].map(|_|i.next().unwrap().parse().unwrap());print!("{}",(0..b).fold(1,|r,_|r*a%m))}/*
-}
x=readLn;main=do a<-x;b<-x;c<-x;print$a^b`mod`c
infix 2 ||~;(||~)=(<);(//)=div;(#=#)=(<);r=1{-
Q\
read a;read b;read m;for((r=1;b--;)){((r=r*a%m))};echo $r;exit
]]a,b,m=io.read("n","n","n");r=1;for _=1,b do r=r*a%m end;print(r)--[[
'
{_,[a,b,m]}=:io.fread([],'~d~d~d');IO.puts(rem(a**b,m));~S|
"=#{a,b,m=Stack[0].to_s.split.map(&:to_i);'/\\';p a**b%m;exit}"*///=##a|#;]]--}
- In Haskell,
q=[[] ]<[[1] ]||~r//r#=#1is valid syntax. However, it raises an error because||~,//, and#=#are all treated as undefined operators. We can define these operators afterward. We have to make sure that the types match, and we can useinfixto change operator priority to make this easier. - In Julia,
#= ... =#supports nested comments, like#=...#=...=#...=#. We have nested comments here, so we have to make sure that=#appears twice to close the comment.
+ Whitespace
#![doc=r#"perl ;n{|!u?:-1}${%&:&*@:}O<}1&/\
q=[[]]<[[1] ]||~r//r#=#1{-0!:0'echo{:d|^/x:2{.d=.".;._2[1!:1]3'<<Q\\
;1||~r//r;~S|1;use bigint;print+(<>+0)**<>%<>;__END__|;' \
var[q,b,c]=(await Bun.stdin.text()).split`\n`.map(BigInt);console.log(q**b%c+``)/*
main(r,a,b,m){for(scanf("%d%d%d",&a,&b,&m);b--;)r=r*a%m;printf("%d",r);} /*=#
print(powermod(parse.(Int,eachline())...))#=!#
(write(modulo(expt(read)(read))(read)))#|"#]fn main(){let s=std::io::read_to_string(std::io::stdin()).unwrap();let mut i=s.lines();let[a,b,m]=[0;3].map(|_|i.next().unwrap().parse().unwrap());print!("{}",(0..b).fold(1,|r,_|r*a%m))}/*-}
x=readLn
main=do
a<-x
b<-x
c<-x;print$a^b`mod`c
infix 2 ||~
(||~)=(<)
(//)=div
(#=#)=(<)
r=1{-
Q\
read a;read b;read m;for((r=1;b--;)){((r=r*a%m))}
echo $r
exit
]]a,b,m=io.read("n","n","n");r=1;for _=1,b
do r=r*a%m end;print(r)--[['
{_,[a,b,m]}=:io.fread([],'~d~d~d');IO.puts(rem(a**b,m));~S|
"=#{a,b,m=Stack[0].to_s.split.map(&:to_i);'/\\';p
a**b%m;exit}"*///=##a|#;]]--}
- Most of the languages here ignore tabs and spaces at the end of a line, so writing a polyglot for Whitespace is easy. We ensured that already-placed spaces and line-breaks could be reused as Whitespace code.
- For some parts of the code, we replaced spaces with vertical tabs (
\v) so that they don't affect Whitespace. - The instructions are as follows:
0000 1:15 push +0 SSSL
0004 2:12 innum TLTT
0008 3:58 push +1 SSSTL
0013 4:4 dup SLS
0016 5:78 dup SLS
0019 6:48 innum TLTT
0023 7:115 retrieve TTT
0026 7:236 push +2 SSSTSL
0032 8:9 innum TLTT
0036 9:10 label <empty> LSSL
0040 11:1 dup SLS
0043 12:22 jz S LTSSL
0048 14:10 swap SLT
0051 15:10 push +0 SSSL
0055 16:10 retrieve TTT
0058 16:13 mul TSSL
0062 17:1 push +2 SSSTSL
0068 18:1 retrieve TTT
0071 18:4 mod TSTT
0075 18:8 swap SLT
0078 19:2 push +1 SSSTL
0083 20:1 sub TSST
0087 20:5 jump <empty> LSLL
0091 23:3 label S LSSSL
0096 25:5 drop SLL
0099 27:37 outnum TLST
0103 28:29 end LLL
While writing this writeup, I found some places where I can reduce the code. The last payload is 1054 1050 bytes, which is 24 bytes less than our final payload during the CTF!
Special thanks
I want to thank all of my team members who contributed to achieving this wonderful result:
- Shiro
- rewhile
- bean
- Yuu
Also, big thanks to Team b01lers, especially the challenge author oh_word, for this wonderful challenge and amazing infrastructure.